Subscribe Top–k Related Twitters To News Stories
##Introduction
本文简要描述了Shraer $et\ al.$在VLDB 2013上的一个工作1:依据内容相关性,将twitters实时注册到news stories中(billions of pageviews per day),维护每个story始终有top-$k$个最相关的twitters。业务上做扩展的情况很多,例如在LBS场景中,可以用来筛选海量信息,将其注册到动态地理位置区域。
本文分为两个部分:(1) primitive techniques:描述信息检索系统中的两种查询处理策略(TAAT and DAAT)以及查询处理中的skipping技术;(2) their contributions1:描述在常规查询处理的基础上做改进,构建一个top-$k$ publish-subscribe系统。
##Query Processing
(1) 查询处理的problem setting
Given:(1) inverted index $I$ of stories $S$, (2) query $u=\{u_1,u_2,…,u_n\}$ and (3) $k$.
Return:top-$k$ related story set $R$ to $u$
Methods:TAAT, DAAT, etc.
无论使用哪种查询策略,都会首先在索引中找到$u$对应的posting lists $\{L_1,L_2,…,L_n\}$(每个term对应一个list)。实际的搜索空间就是这个list set。
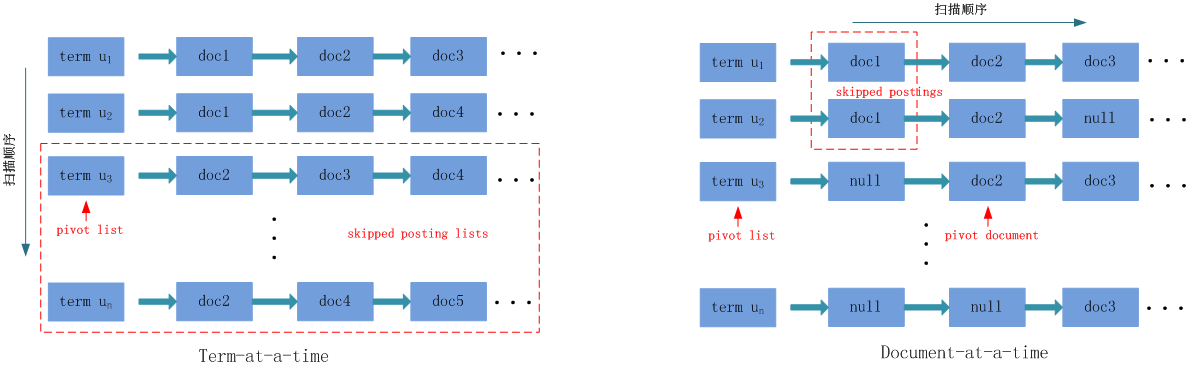
(2) Term-at-a-time (TAAT)
TAAT采用纵向扫描的策略:从上到下依次遍历每个posting list,遍历过程中对相应的document增加得分,最后将document按得分逆序输出(截取前$k$个)。
(3) Document-at-a-time (DAAT)
DAAT采用横向扫描的策略:(a) 事先将posing list中的documents按doc id升序排序,并对每个posting list都保留一个当前位置指针;(b)对于所有的当前位置指针,取doc id最小的那个,计算该document的得分,并将相应的指针往后移动一位;(c) 重复上述b过程直至所有posting list都被遍历完。最后将documents按得分逆序输出。
(4) Discussions
TAAT和DAAT各自的优点也是对方的缺点:(a) TAAT需要在内存中保存所有documents的分值累加器,而DAAT只需要保存一个size为$k$的min-heap;(b) 由于posting list一般是顺序存储在disk blocks中的,因此DAAT需要在blocks之间跳跃寻址,而TAAT不用。
另外,查询处理所找出来的top-$k$ rank是coarse的,作为候选集,后续还需要用机器学习方法做fine tuning。从内容角度来说可以利用neural word embedding,从模型角度来说可以结合用户喜好等外部信息。
##Skipping Techniques
(1) 什么是skipping技术
skipping技术的种类很多,目的是为了提高效率,主要思想是在search过程中跳过一些对结果无影响或影响较小的posting lists或postings。
比如,approximately search会选择跳过一些page rank值较小的documents;或者将生僻的terms作为必要查询条件(先search那些生僻terms对应的posting lists,这样一来其他posting lists可以跳过好多无关的documents)。
下面两节分别描述TAAT和DAAT策略是怎样exactly (相比approximately) skip posting lists的。主要思想都是确定一个upper bound(UB for short),然后估计会不会连UB都够不着top-$k$。
(2) skipping in TAAT
首先定义posting list $L_i$的upper score:$ms(L_i)=\operatorname{max} ps(s,i)$。其中,$ps(s,i):=\frac{cs(s,u_i)}{u_i}$表示term $u_i$对于$cs(s,\cdot)$的贡献值,分母是$u_i$在story $s$中的权重(比如$\log(tf)$)。$cs(s,u_i)$是content based score,可以用vector cosine、BM25等作为measures。
TAAT将posting lists按照ms值降序排序,逐条评估。评估前检查下面的条件,如果满足就一次性skip掉剩下所有的posting lists。$L_i$可以称为pivot list。
不等式左边是UB。$A_k$表示第$k$大的document分值累加器。上述条件表示,如果第$k+1$大的文档分值加上剩下所有posting lists的最大分值都超不过$A_k$,就不用费劲去评估剩余的posting lists了。
贡献度大的terms会被优先评估,这是skipping策略奏效的前提。如果query中terms的ms值都差不多,说明terms的贡献程度也差不多,这个skip策略就意义不大了。
(3) skipping in DAAT
DAAT的skip技术采用迭代的方式,每次迭代都试图skip a batch of postings (注意与TAAT不同,这次是postings,不是posting lists)。为了这个目的,每次迭代时都要对posting lists重新排序,排序依据是各个posting lists当前指针指向的doc id(升序顺序)。DAAT每次找一个满足下面条件的pivot list $L_i$,并把pivot list当前指针指向的posting称为pivot document。可以skip掉$L_j$中所有doc id小于pivot document的postings,因为它们的最大值(UB)都不会大于$A_k$。
由于依赖于doc id的顺序,所以skipping效果会比较随机。
(4) Discussions
通俗地讲,TAAT以term为单位进行skip,而DAAT以document为单位进行skip。很多实际应用中,$u$的size较小,而posting list的average length较长,因此DAAT的实际效率会比TAAT的效率高。
上面提到的两种策略都只考虑skip整个posting list,也有一些其他文献skip partial list,我没考察过。但Shraer $et\ al.$的工作做了部分相关工作,在下节中有描述。
##Pub-Sub for Annotating News Stories
终于要开始讲Shraer $et\ al.$1的工作了,他们的工作内容总结起来就是两点:(1) 在常规查询处理的基础上做改进,构建一个top-$k$ publish-subscribe系统;(2) 修改了常规skipping策略,使得这些策略在Pub-Sub系统中仍然奏效。所有的工作都是基于内存的,所以能做到实时;采用恰当的存储管理策略,也会达到类似的近实时效果。
(1) publish-subscribe system
我们的目的是要维护每个news story都能实时获取到top-$k$个最相关的twitters。所谓实时,就是stories是实时生成的(hundreds per minute),twitters也是实时生成的(tens of thousands per minute),而pub-sub系统能始终保持它们的注册关系是fresh的。
从数量级的差异上看,stories是subscriptions,而twitters则是published-items。通俗地说就是twitters往stories上注册。每个story都保存一个size $k$的min-heap,元素就是twitters,值就是内容相似度。
现在只考虑newly coming twitters,原有的problem setting做如下修改即可。
Given:(1) inverted index $I$ of stories $S$, (2) query $u=\{u_1,u_2,…,u_n\}$ and (3) $k$
Update: size $k$ min-heaps $R_{s}$ for all stories
Methods: variations of TAAT and DAAT
可以发现,任务发生了变化,不需要返回最相关的前$k$个stories了,而是更新相关stories的min-heaps。这样,在原有查询处理的基础上只多了一步操作,就是在计算twitters与stories的相似度后,把twitters往stories的min-heap里扔进去。需要牢记一点,就算story $s$在twitter $u$的top-$k$ related stories之中,反之却不一定。 因此原有的skip conditions不满足了,需要改进,下面两节会做相关描述。
最后一个问题,如果有新的story进来,则要在插入story index前先去一个小规模但比较新的twitter index(需要维护这样一个索引)中做下传统查询处理。论文[1]的图1中有展示这个architecture。
(2) skipping techniques in pub-sub system
(a) skipping in pub-sub TAAT
首先定义story $s$中min-heap的顶部元素为$\mu_s$(即与$s$最不相似的那个term)。这次的UB有点loose了,新进来的term要比每个$\mu_s$都更不相似,才能skip整条posting list。余下的posting lists也无法保证,只能一条一条评估。
不等式左边给出了UB,$A_1$是当前的最相似story对应的current similarity。这个分值加上剩下所有posting lists的最大分值都足够小,就skip掉整个posting list。其实可以在内存里记住这些skipped postings,评估其他posting lists时也可以直接无视它们。
(b) skipping in pub-sub DAAT
pub-sub DAAT沿用DAAT原有的skip condition,只是将$A_k$替换成$\mu_s$。这次只能一个一个评估posting。
(c) partially skipping
很显然,在pub-sub系统中无论是TAAT还是DAAT,改造后的skip conditions都非常宽松,效果大打折扣。TAAT从skip a batch of posting lists缩水为skip a posting list,DAAT从 skip a batch of postings缩水为skip a posting。实际上,TAAT其实跟DAAT类似,也相当于在一个个地skip posting。
因此Shraer $et\ al.$提出partially skipping策略。即考察每个posting list时,都试图快速跳到第一个违反skip condition的posting,前面的那些postings就自然skip掉了。他们使用树结构来加速这一跳跃过程。
对于每个posting list,都建立一棵balanced binary tree来索引其中所有的postings。实践中,每个叶子节点都包含一定size的posting set(size根据内存大小定)。从左到右以叶子节点为单位,postings按照原有posting list中的顺序排列。每个节点(包括非叶子节点)的索引值都是这个节点包含的postings中最小的$\mu$。论文[1]的图2有展示这棵树的结构示意图,每次迭代都在这棵树中快速检索下一个违反skip condition的posting(很明显迭代顺序是从左至右的扫描树节点)。
正是上述posting粒度的skip condition才催生了这一partially skipping策略。
##Reference