Neural Word Embedding: Applications And Explorations
##Introduction
Neural word embedding使用上下文来编码word,编码信息在词之间发生多次传递和更新后(thru NN-architecture),训练得到的word vectors在某些代数运算下表现出一定的语义和语法意义。例如,向量cosine可以衡量语义(语法)相似度,而向量相减则表达某些语义(语法)关系。
本文分为两部分:(1) applications, 描述作者在训练和使用distributed word representation中的一些个人经验;(2) explorations, 简要描述word embedding扩展工作现状和作者的个人理解。
###Application: Context Construction
作者使用word2vec toolkit123 (c语言版本) 来训练词向量。word2vec以两个换行符间的词序列作为一个处理单元,如果其中包含的词数超过1000,则将其分裂成两个单元,以此类推。算法会在处理单元内部滑动窗口(窗口大小一般为5-10)来获取上下文。
作者比较了两种构造上下文的方法。
(1) 直接构造法:corpus为一个文件,每个sentence为一行,sentence经过分词后以空格分隔,按原始顺序排列。
(2) 间接构造法:corpus为一个文件,每个document为一行。对document做keyword extraction,得到words及其weights。挑选权重最大的前100个词,以空格分隔,任意顺序排列。调整窗口大小为50,即采用document中的所有词来构造其中每个词的上下文。
»» Experiments and Discussions:
作者分别对两种上下文构造方法生成的训练集运行word2vec toolkit,并计算$k$-nn ($k$=40),结果如下图所示(左侧是直接构造法的结果,右侧是间接构造法的结果)。
(1) 【长处】直接构造法的上下文距离较近,更侧重语法(搭配);间接构造法的上下文距离较远,更侧重语义。
(2) 【短处】直接构造法容易引入噪声相关词;间接构造法可能引入较远的语义。
(3) 【效率】间接构造法的效率更高:(a) 处理单元的数量有效减少;(b) 抽取关键词使得词频降低了(每个document中的word最多出现一次),而word2vec toolkit会筛除低频词。
根据应用场景和计算资源的不同,可以选择不同的上下文构造方式,或者可以把两种构造方法对应的word vector做连接(这里会有个处理平滑的问题)。个人觉得,语义粒度较细的matching task可能更适合直接构造法,而语义粒度较粗的classification task可能更适合间接构造法。

###Application: Classification Task
如果能直接训练出distributed paragraph representation,则文本分类的输入就可以替换为paragraph vectors。但是,在模型复杂度和语料库规模都有限的当下,还做不到这一点。即便如此,借助word vectors仍然可以提高分类准确度。较为intuitive的想法是解决一意多词的问题(plsa也可以)。例如,“乔布斯”和“Jobs”的语义距离较近(在大多数语料中它们表示同一个人),因此可以把它们映射到同一个id后,再作为文本分类器的输入。映射这件事可以用聚类算法(e.g., $k$-means algorithm)等算法完成,约束cluster size不要太大(根据分类的粒度粗细决定)。
一种误区是:averaging weighted word vectors to paragraph vector。不可行的原因是:(1) word vectors的维度太低;(2) 只能span到一个affine space;(3) 缺少words在paragraph中的relations信息;因而不足以表达稀疏且高维的paragraph space。
###Application: Matching Task
虽然简单把词向量加起来无法表达paragraph的完整语义,但在matching task中却已经足够了。前提是,通过IR等方式已经获得了一些靠谱的候选集。这很容易实现,从document的keywords中选出前5个权重最大的词,到倒排索引中做布尔查询即可。然后按照加权词向量的cosine值做降序排序即可返回top-$k$ results (neither no less than the predefined threshld)。
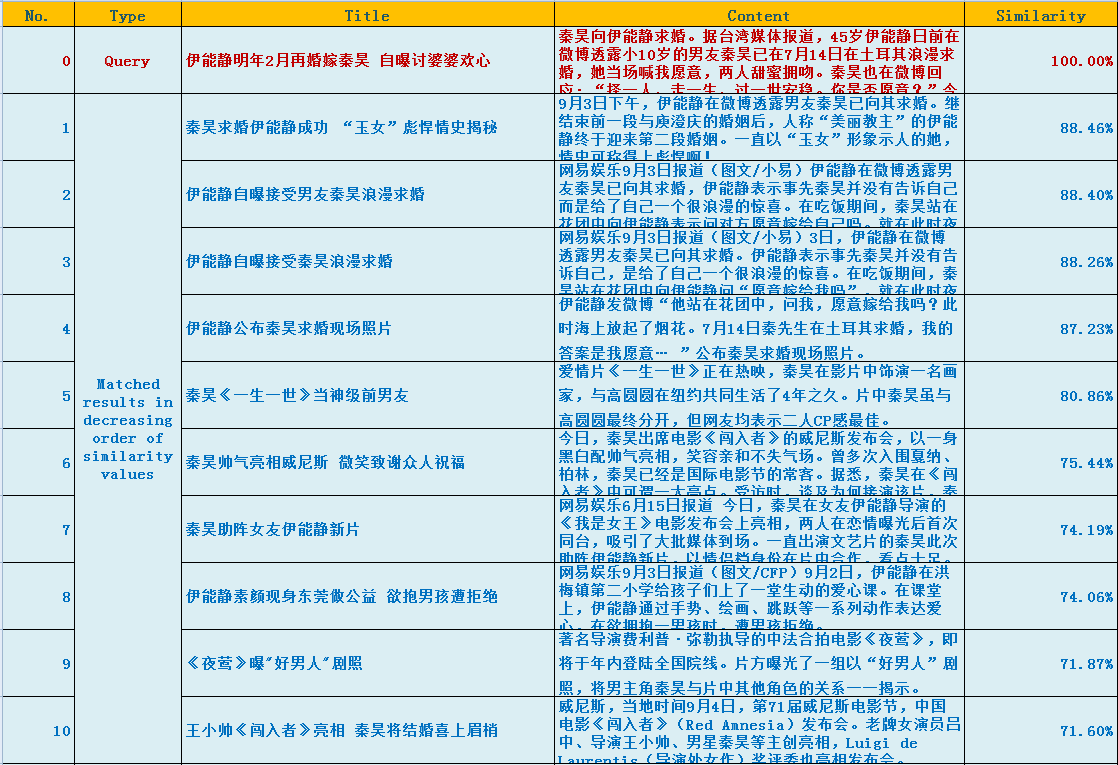
词向量加权在这里起微调作用,因为paragraph最主要的部件(权重最大的5个关键词)在IR系统中已经匹配到。下面是匹配效果举例。
###Exploration: Paragraph Embedding
与word embedding相比,paragraph embedding必然还要加入词之间的相互关系。这里涉及到两个问题:(1) 怎样构造word relation;(2) 怎样设计NN-architecture。
(1) 怎样构造word relation?(a) 采用n-gram model是较为general的方法,但是由于paragraph space的稀疏性和高维特点,较小的n提供的信息不够,较大的n则需要bigger than bigger data来训练;(b) 通过统计模型估计词之间的依赖关系,建立小规模的word graph(例如,基于句法结构的分析结果,从中抽取与关键词有关的依存关系)。
(2) 怎样设计NN-architecture?(a) 编码内容:bag of words、word graph、other attributes of paragraph;(b) 编码目标不应该是paragraph,而是topic,再由topics来生成paragraphs(反过来理解,就是paragraph space投影到一个或多个topic spaces)。
Le $et\ al.$4利用skip-gram architecture,在word context中加入paragraph id,做出来的paragraph embedding效果并不是很好。从实验中也可以看出部分问题:(1) 因为考虑了the order of words,就会面临数据稀疏的问题,而实验语料又是这么小规模;(2) paragraph的维度竟然跟word的维度是一样的,实验中都是400维;(3) 有关IR的实验其实假设了已经有了一堆靠谱的候选集,用weighted average of word vectors也能达到一样甚至更好的效果。
###Exploration: Semantic Relations Based on Word Embedding
还有一些文献考察了word vectors代数运算所表达的语义关系。例如,Levy $et\ al.$5利用cosine运算的语义(语法)含义,构造了两种方法(3COSADD and 3COSMUL)来search analogy object,可以作为衡量词向量表达能力的度量方式。再例如,Fu $et\ al.$6试图用向量差来衡量某种hierarchical关系,训练数据是一个非常小规模的层次树数据集,可能是直接拟合效果不行,作者用采用了聚类等方式来分情况拟合。
直觉上讲,上述两种尝试都是基于这样的假设:word vectors是由其上下文编码的,上下文的差异(对应向量相减等运算),描述了词之间的某种关系(层次关系、类比关系等)。但是,代数运算可表达的关系可能是复合的,无法分解的。因此,个人觉得这些尝试只能是点到为止,不应是主要研究方向。
##References
-
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. In Proceedings of Workshop at ICLR, 2013. ↩
-
Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of NIPS, 2013. ↩
-
Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic Regularities in Continuous Space Word Representations. In Proceedings of NAACL HLT, 2013. ↩
-
Quoc Le and Tomas Mikolov. Distributed Representations of Sentences and Documents. In Proceedings of ICML, 2014. ↩
-
Omer Levy and Yoav Goldberg. Linguistic Regularities in Sparse and ExplicitWord Representations. In Proceedings of CoNLL, 2014. ↩
-
Ruiji Fu, $et\ al.$ Learning Semantic Hierarchies viaWord Embeddings. In Proceedings of ACL, 2014. ↩